


您的购物车是空的,快去添加商品吧

以下为来信正文
OK的家长们:
你们好!我是贾云海!
受新冠疫情的影响,自1月23日武汉封城起,普通民众自行隔离在家,已经一月有余了。
可喜的是,疫情已经迎来向好拐点,我们看到,截止今天,除武汉外,新增确诊病例、新增疑似病例已经双双归零。
在之前的来信中,我提到了拐点之于疫情和孩子学习的重要性。(点击链接查看)
今天呢,我们还是基于“拐点”来聊聊疫情。
自疫情开始,就不断有人把2003年的非典疫情和今天的新冠疫情做对比。
而对比下来后,有一个明显的现象:
2020年的今天,几乎是全民都在谈论“拐点”,拐点成了一个微博热词,每个人都在期待拐点;
而在2003年,“拐点”这个词,甚至都很少出现在相关的新闻报道中。
那么,十七年后的今天,我们凭什么能大谈“拐点”呢?
01
1. 今天,我们怎么找到拐点
对于今天的“抗疫战”来说,有一个很重要的战场,那就是“信息战场”。
2003年,在疫情爆发的高峰期,仍有两万名观众涌入天河体育场,观看罗大佑演唱会。别说实名制的演唱会门票,甚至连火车票,也是2012年才全面实行实名制的。
17年后,在大数据的帮助下,通过追踪每一个人的移动轨迹,通过交通、电信、地图等信息的自动汇合,最终生成人员移动的精准轨迹,是否和疑似人员有过接触、是否到过疫区,全部一目了然,甚至能够根据确诊人,追查到所有疑似患者。
我们不但能够清晰的看到全国各地的迁入、迁出信息,更能随时监控国内外疫情数据。
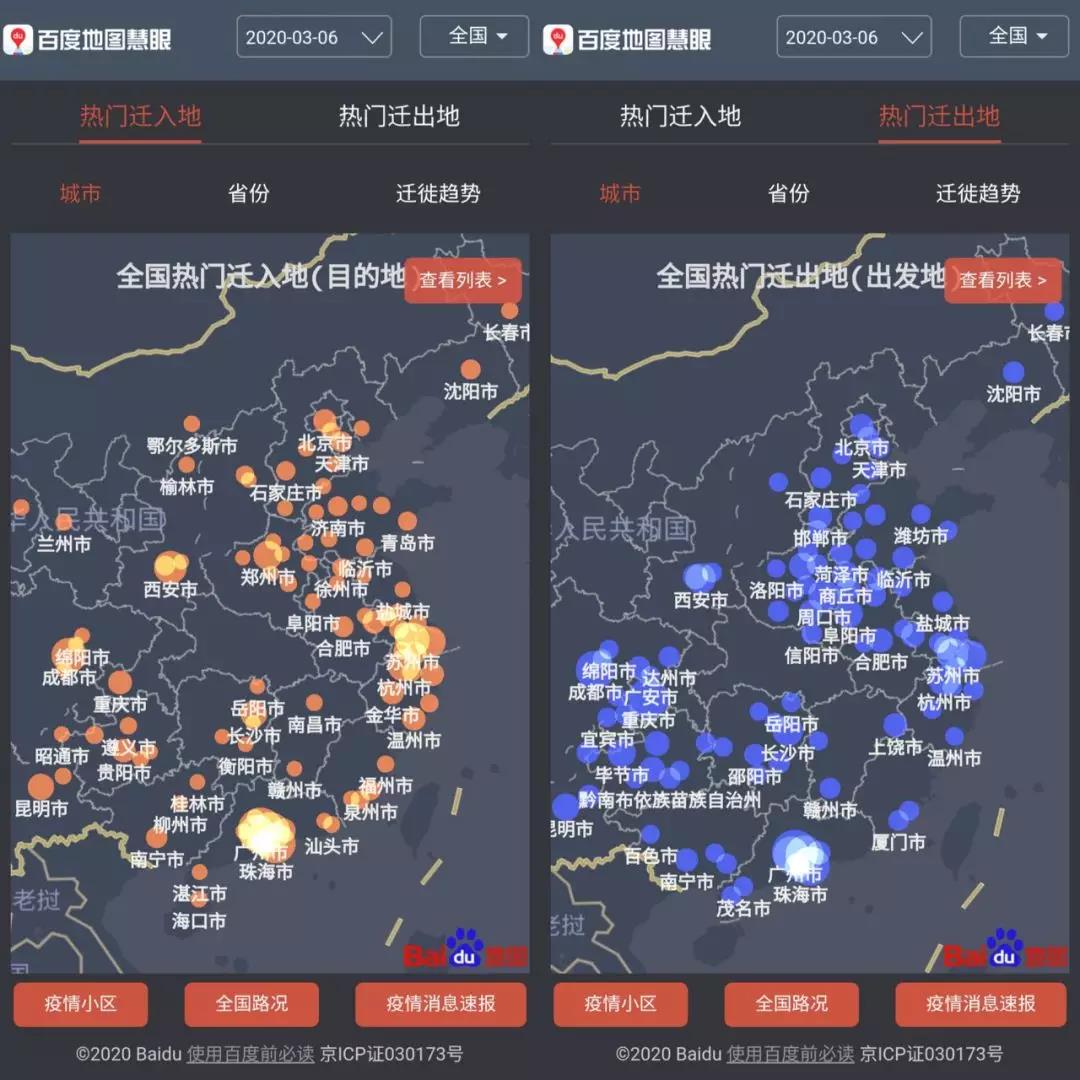
(人员迁徙地图 来源:百度地图慧眼)
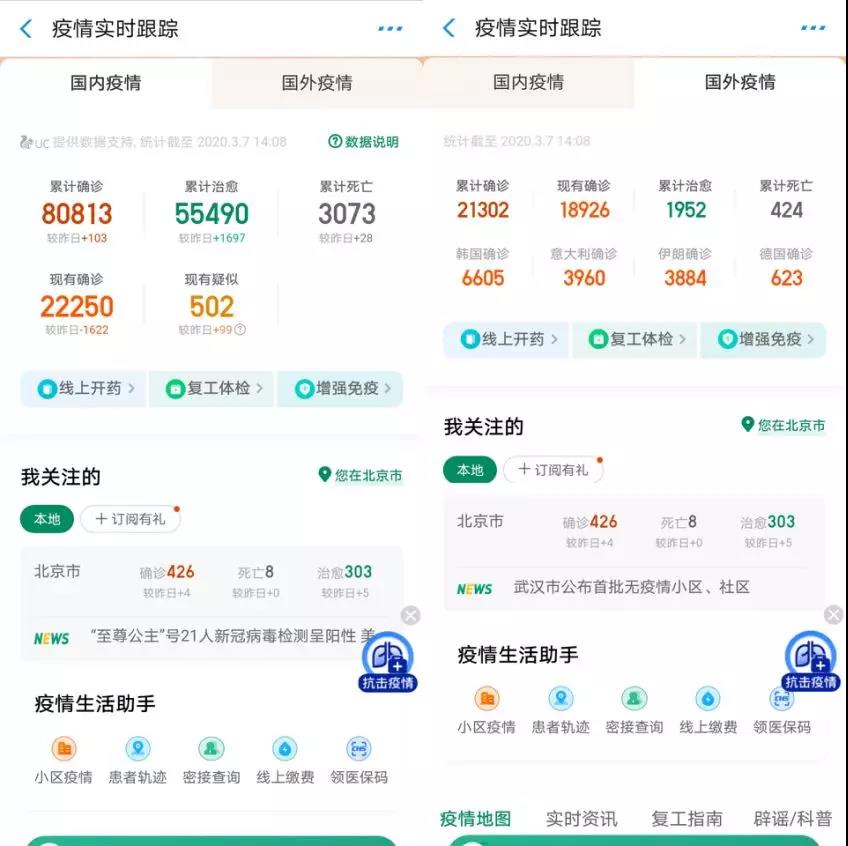
(国内外疫情实时跟踪 来源:支付宝)
下面的视频中,就详细讲述了在新冠疫情的防控过程中,AI、大数据、云计算发挥的重要作用。
https://mp.weixin.qq.com/s/pCbXlN2HJ-2mC7L8lpKvXg
(进入链接,在原文中观看视频)
也就是说,相较于2003年,十七年后的今天,我们之所以能够大谈“拐点”,其中一个非常重要的原因就是——依赖于数据技术的发展,信息公开透明的程度越来越高,我们也能够更加准确的预测拐点了。
下图是钟南山团队近期在《胸部疾病杂志》上发表的论文中,基于SEIR 模型做出的感染人数预测图。
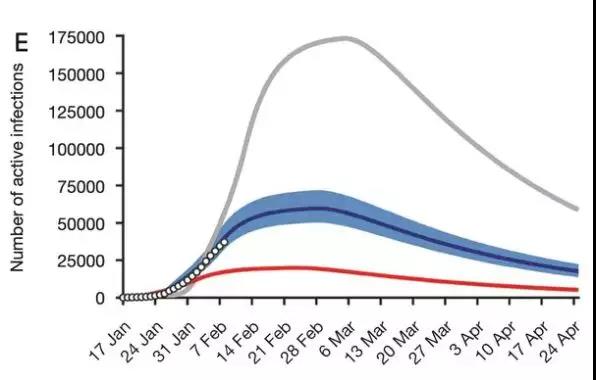
其中, 蓝色线为1 月 23 日采取干预措施的情况、灰色线为推迟 5 天采取措施的情况。
也就是说,如果因为信息不透明等各种原因,1月23日没有及时采取干预措施,或者干预措施没有奏效,而是推迟5天,那么,截止2月25日,湖北省的感染人数,将会达到115061例,远高于现在的峰值。
所以,对于这次疫情来说,疫情爆发后的信息公开透明,无疑是锁定疫情拐点的一剂“特效药”。
2、今天,我们如何应对拐点
下面的视频,最早出现在疫情爆发拐点出现之后,河南村长的硬核广播喊话在网络上疯传,倡导村民春节不走亲访友,自行隔离在家。
https://mp.weixin.qq.com/s/pCbXlN2HJ-2mC7L8lpKvXg
(进入链接,在原文中观看视频)
视频一出,立刻传遍网络,全国各地纷纷效仿,这种幽默且接地气的广播形式,不仅缓解了民众紧张焦虑的心情,更重要的是,在疫情大规模爆发的拐点出现后,提高了宣传应对的效率。
而我们试想一下,如果这位村长的喊话,放在2003年,还能起到这么好的应对效果吗?
恐怕不能。
先不说这段视频能不能火遍全网,以当年的科技发展水平,有摄像功能的手机,甚至都在少数。
2003年,互联网用户只是小众群体,大部分人获取重要信息的渠道,依旧是电视、广播、报纸等传统媒介。
17年后,互联网已经成为普通民众最重要的获取信息的渠道,除却传统媒体,手机中的各个APP,随时随地为人们提供最“新鲜”的信息。
也就是说,当信息公开透明的程度越来越高,相应的,也就提高了应对拐点的效率。
02
回到学习中的拐点。
在之前的来信中,我曾说过,知识之间的阶点是客观存在的,孩子就必然存在他可能迈不过去的拐点,而拐点的存在,甚至会导致孩子的成绩,出现断崖式的下滑。
这是学习中普遍存在的一个问题。
那么,为什么10年之前,教育中很少提起拐点,也很少提到要帮孩子解决学习拐点呢?
因为,太难了。在当时,想要判断孩子学习的拐点出现在哪儿,大部分情况下,需要依据老师的经验判断。然而即便老师有经验,但他没时间关注到孩子的整个学习过程,那么,判断难度依然很大。
而今天,我们又凭什么大谈拐点呢?
也是因为,随着数据技术的发展,孩子们的学习数据能够被实时的收录、分析,老师和家长就能基于这些清晰透明的数据,来帮助孩子找到他的学习拐点,并制定最适合他的学习计划。
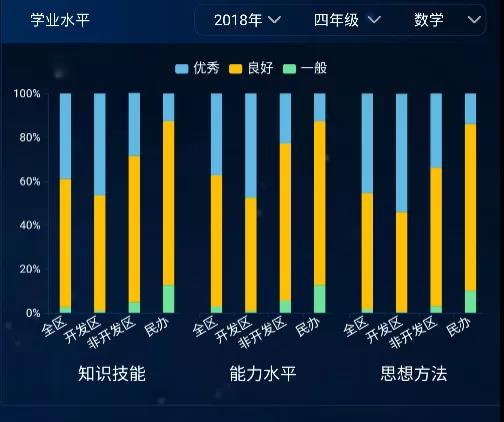
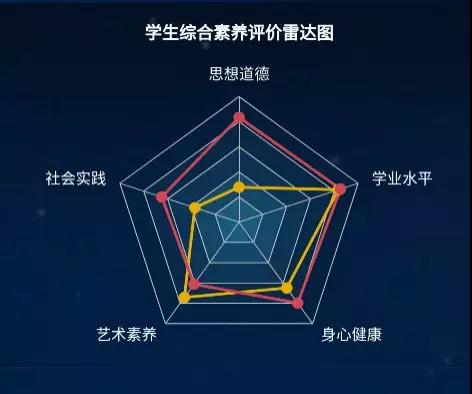
如下图所示,学生的数学学业水平,以及学生综合素养水平,通过数据分析后被更加清晰的展示了出来。
斯坦福大学的吴恩达教授,曾经开设了一门叫“机器学习”的课程,他从课程的大数据中发现,有大量学生会做错一道“计算成本”的线性回归题,但是在浏览了第830篇论坛文章后,有64%的学生可以自我纠正。
于是,当后面的学生再犯同样错误的时候,系统就会自动为学生推送第830篇论坛文章,为他们答疑。
也就是说,我们可以分析、记录孩子的学习数据,让孩子的学习过程透明化,这样一来,在定位孩子学习拐点时候,就有了重要依据。
在使用OK学习机的孩子当中,也有这样的例子,拿我印象比较深的一个来说:
初中三年,这个孩子的地理成绩总是低空飞过。家长当然很发愁,想要帮孩子解决这个问题。
然而学不好地理这件事儿,原因太多了,想要依靠传统的方法来找到孩子的拐点,难度其实不亚于蒙眼狙击。
但是,当孩子的学习有技术支撑后,他的做题过程被实时记录,综合对大数据的集中分析,最终发现,导致孩子地理成绩上不去的根本原因,不是逻辑能力不行、不是阅读能力不行,而是因为几根经纬线——因为孩子始终不明白,地球上为什么要画横横竖竖的线。
你看,如果这个问题能尽早通过公开透明的学习数据展示出来,那么,孩子的这个拐点,就能更早得到解决。
所以,学习信息的透明化,不仅提高了锁定孩子学习拐点的准确率,更能提高应对拐点、解决拐点的效率。
特别是最近一段时间,由于疫情的缘故,孩子们不得不在家学习。
在这种情况下,我不建议孩子们着急学习新的知识,超前学习,而是更建议孩子们利用这段时间,着重解决之前学习遗留下来的拐点。
要依靠数据,让孩子们清晰的看到,哪些内容是重复在做的无效内容,哪些内容是需要重点攻克的有效内容。
要让孩子在数据的指导下,学自己不会的知识点,做自己最该做的那道题,有针对性的学习,这才是提高学习效果有效的途径。
今日寄语
最后,想和大家说,虽然眼下疫情迎来了向好拐点,但整体来看,并没有到完全放松警惕的时候。
在这种情况下,贸然的聚集,不注意防护,很可能会加大疫情反弹的风险。
下面的视频,是一位网友通过计算机模拟的方式,表现了疫情期开学可能会产生的后果。
https://mp.weixin.qq.com/s/pCbXlN2HJ-2mC7L8lpKvXg
(进入链接,在原文中观看视频)
所以,不贸然聚集,不放松警惕,是眼下需要特别注意的。真正的大规模复工复学的拐点,还需要我们耐心等候。
以上,就是我今天想要分享给大家的内容。如果你还有任何问题,欢迎给我留言,我和我的团队将为你答疑解惑。


